Documentation Index
Fetch the complete documentation index at: https://launchdarkly-preview.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
 Hardcoded multi-agent orchestration is brittle: topology lives in framework-specific code, changes require redeploys, and bottlenecks are hard to see. Agent Graphs externalize that topology into LaunchDarkly, while your application continues to own execution.
In this tutorial, you’ll build a small multi-agent workflow, traverse it with the SDK, monitor per-node latency on the graph itself, and update a slow node’s model without changing application code.
Hardcoded multi-agent orchestration is brittle: topology lives in framework-specific code, changes require redeploys, and bottlenecks are hard to see. Agent Graphs externalize that topology into LaunchDarkly, while your application continues to own execution.
In this tutorial, you’ll build a small multi-agent workflow, traverse it with the SDK, monitor per-node latency on the graph itself, and update a slow node’s model without changing application code.
- Node = AI Config (model, instructions, tools)
- Edge = handoff metadata (routing contract you define)
- Graph = topology (which nodes connect)
- Your app = execution + interpretation
What You’ll Build
In this tutorial, you’ll add Agent Graphs to an existing multi-agent workflow:- Build a graph visually in the LaunchDarkly UI
- Connect it to your code with a few lines of SDK integration
- Run your agents and see the graph in action
- Monitor performance with per-node latency and invocation tracking
- Fix a slow agent by swapping models from the dashboard
Prerequisites
- LaunchDarkly account with AI Configs access (sign up here)
- Python 3.9+
- An existing agent workflow (or use our sample repo)
The Problem with Hardcoded Orchestration
Every multi-agent framework handles orchestration differently:Why Externalizing Topology Helps
If you’ve built multi-agent systems with LangGraph, OpenAI Swarm, or Strands, you’ve hit these walls:- Config duplication: Agent definitions scattered across framework-specific formats
- Silent failures: An agent times out and you don’t know until users complain
- No topology visibility: The workflow exists only in code
- Custom observability: Getting consistent per-agent metrics means reconciling different trace formats and data schemas across frameworks
For a detailed comparison of LangGraph, OpenAI Swarm, and Strands, see Compare AI orchestrators. Agent Graphs work with multiple agent frameworks.
- See your entire workflow at a glance, not buried in code
- Monitor per-node metrics overlaid directly on the graph (latency, invocations, tool calls)
- Add or remove agents without changing traversal logic, provided your runtime supports the node’s tools and output contract
- Inspect routing logic on edges, with handoff data visible in the UI
- Use graph-aware SDK methods like
is_terminal(),is_root(), andget_edges()instead of manual tracking
Step 1: Create AI Configs for Your Agents
Before building a graph, you need AI Configs for each agent. If you already have AI Configs, skip to Step 2.See the AI Configs quickstart or run the bootstrap script in our sample repo:
- supervisor-agent: Orchestrates the workflow and routes queries based on PII pre-screening
- security-agent: Detects and redacts personally identifiable information (PII)
- support-agent: Answers questions using dynamically loaded tools (search, RAG)
Step 2: Build the Graph in the UI
This is where Agent Graphs diverge from code-based orchestration. Instead of writingadd_edge() calls, you’ll see your topology and modify it visually.
Open your LaunchDarkly dashboard and navigate to AI > Agent graphs.
- You’ll see the first-time setup wizard. Since you already created AI Configs in Step 1, expand Create a graph at the bottom.
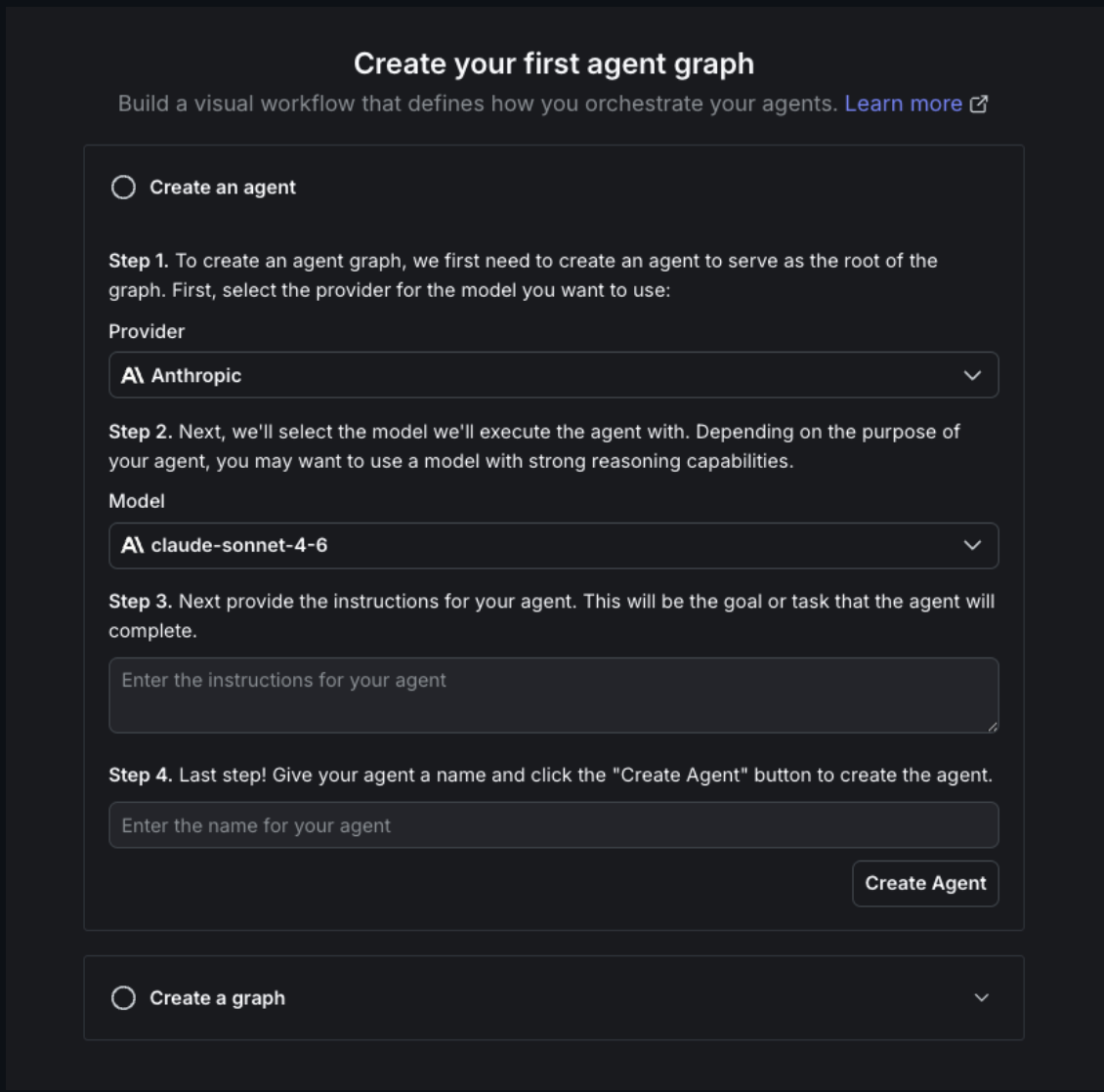
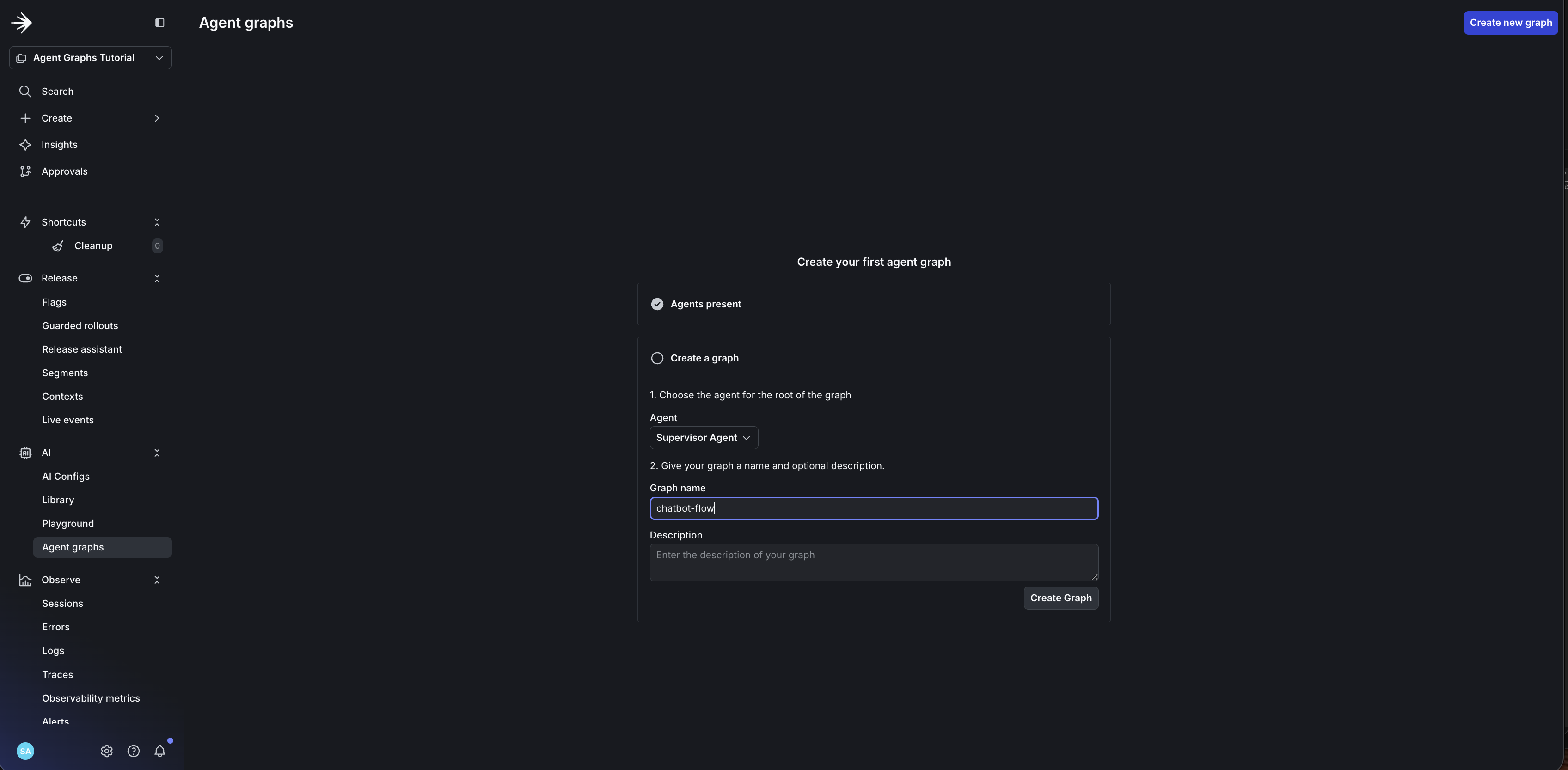
- Name your graph
chatbot-flowand click Create graph.
- Add your first node: click Add node and select
supervisor-agent - Set it as the root: click the node and toggle Root node
- Add
security-agentandsupport-agentas nodes
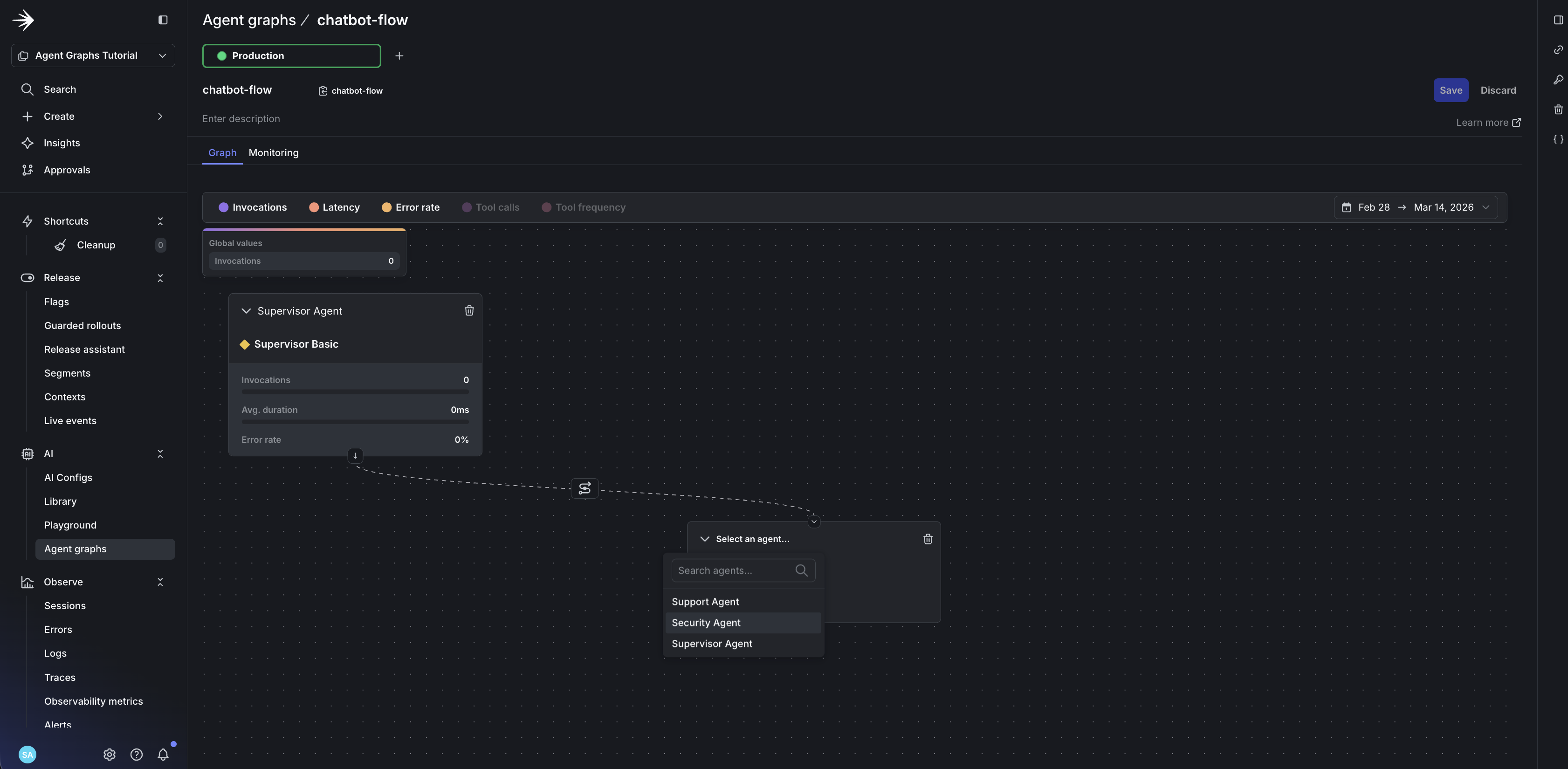
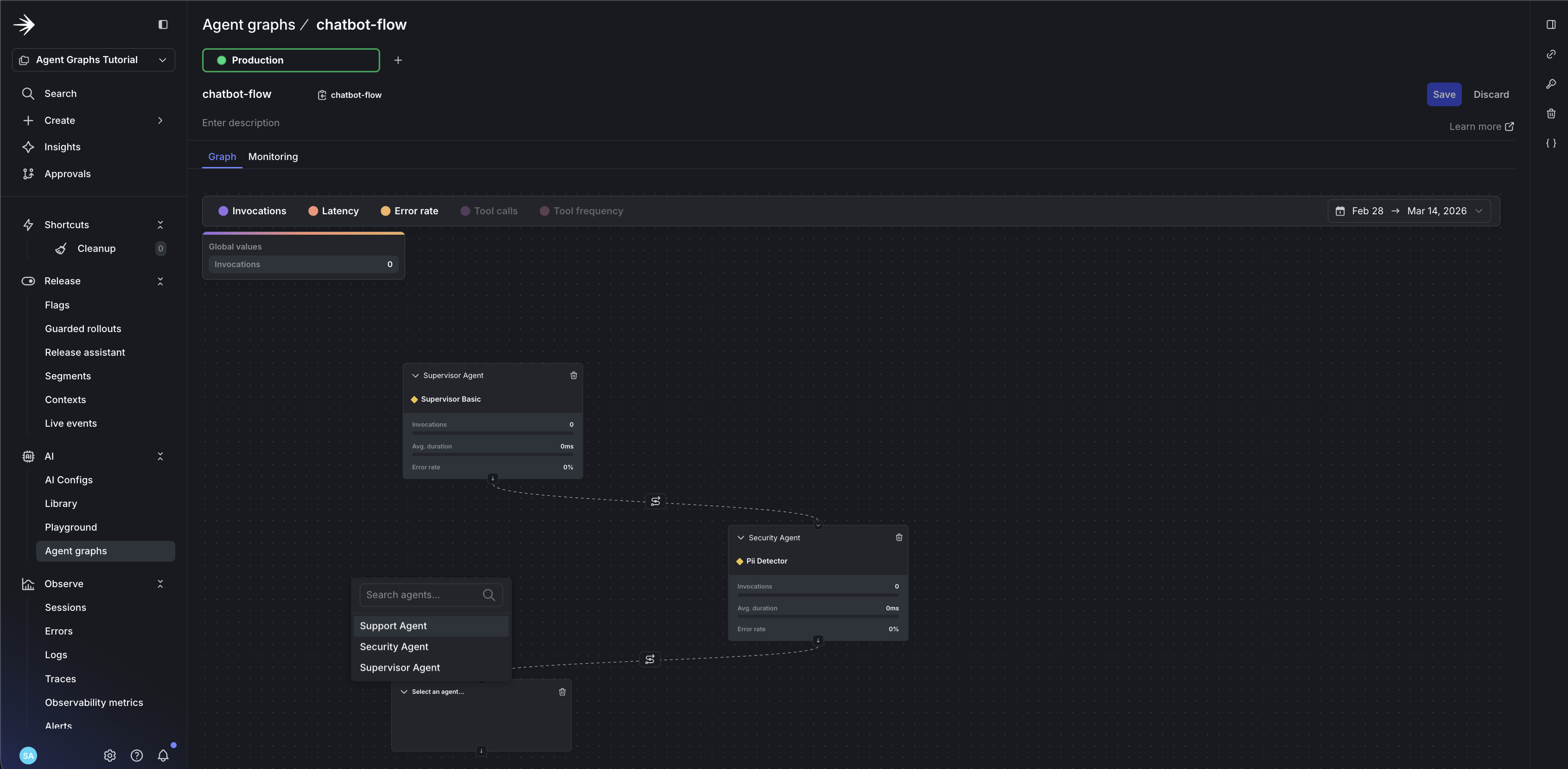
- Draw edges: drag from
supervisor-agentto both child agents - Add handoff data to each edge to define routing logic:
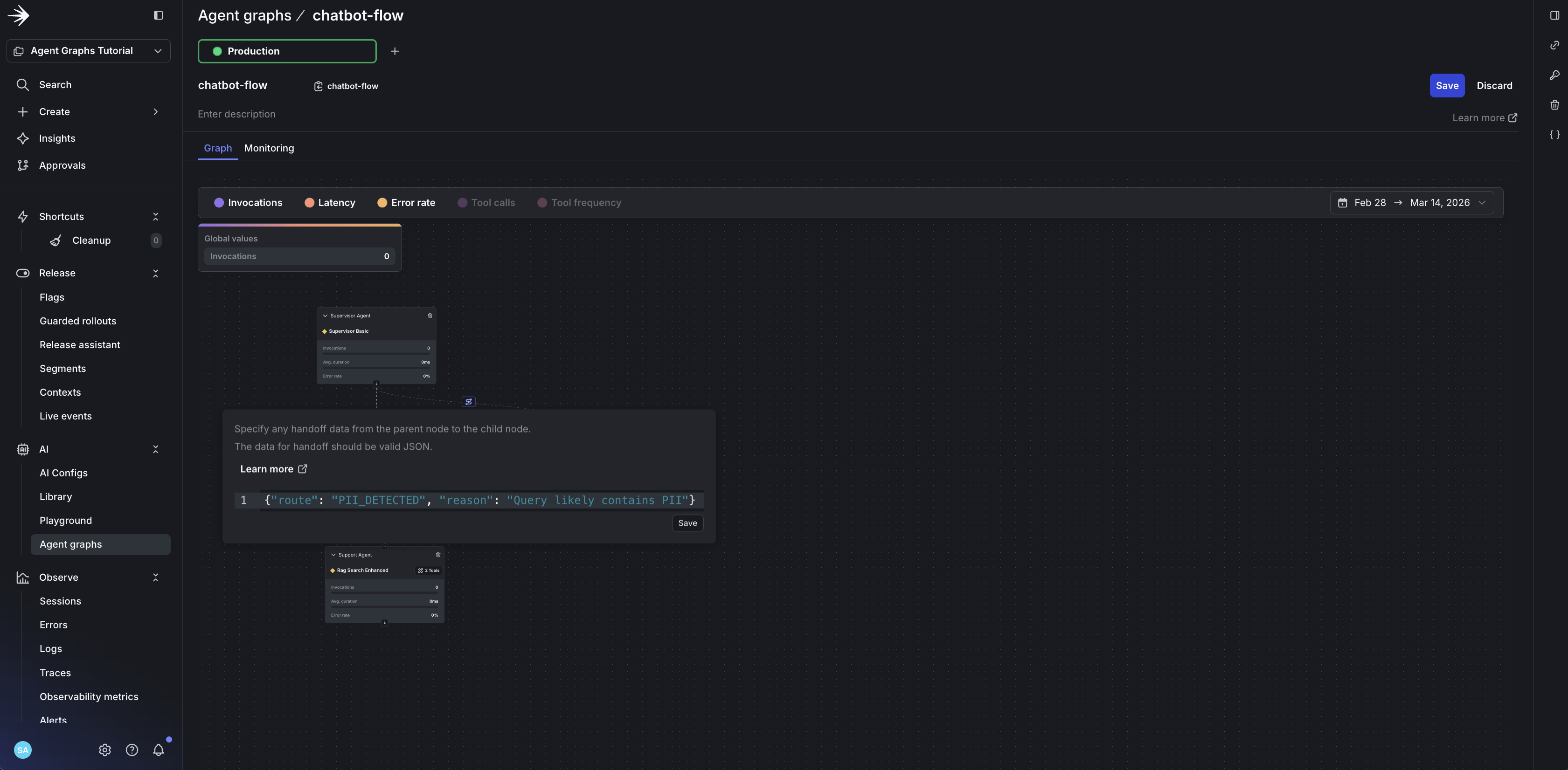
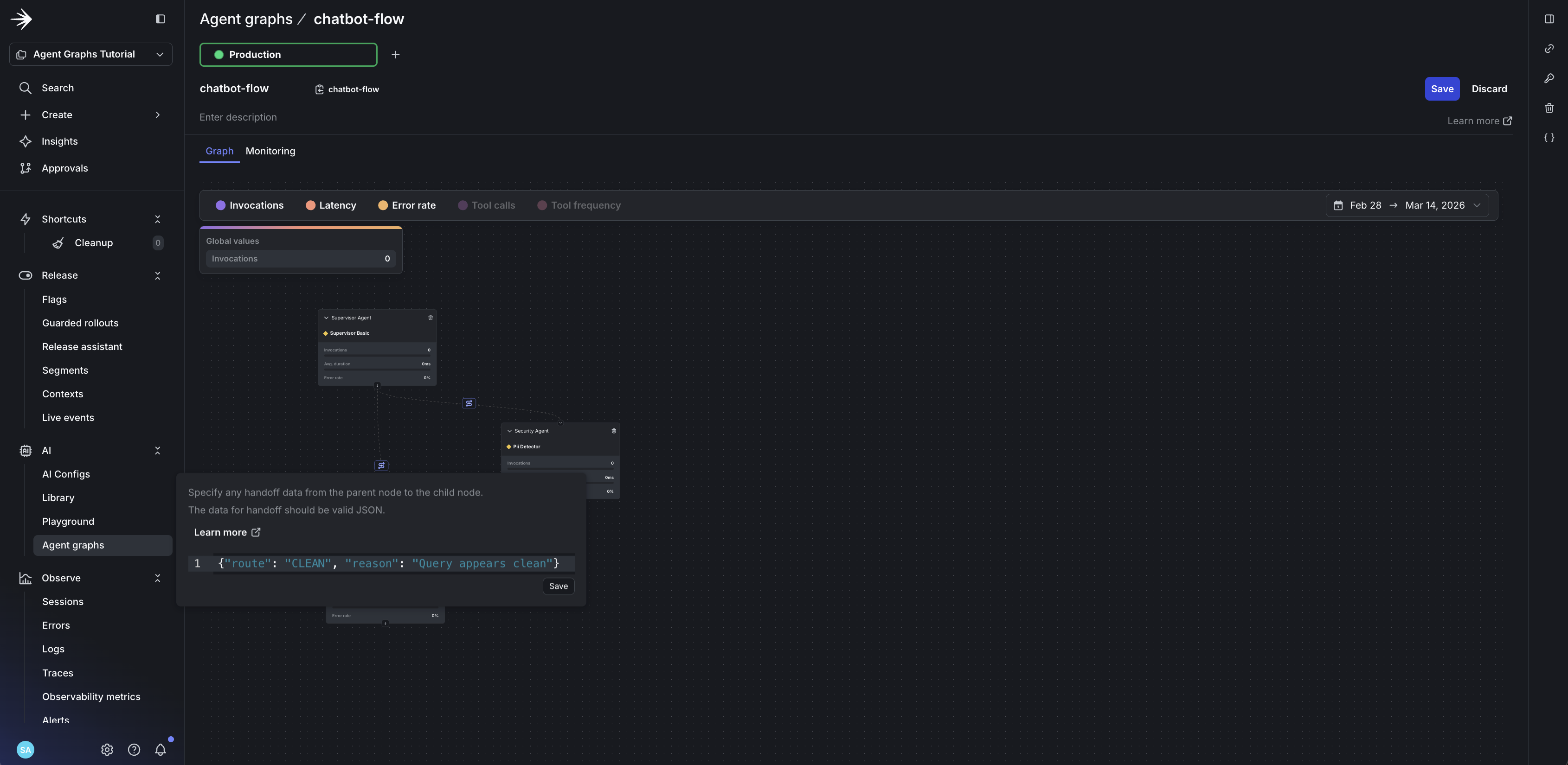
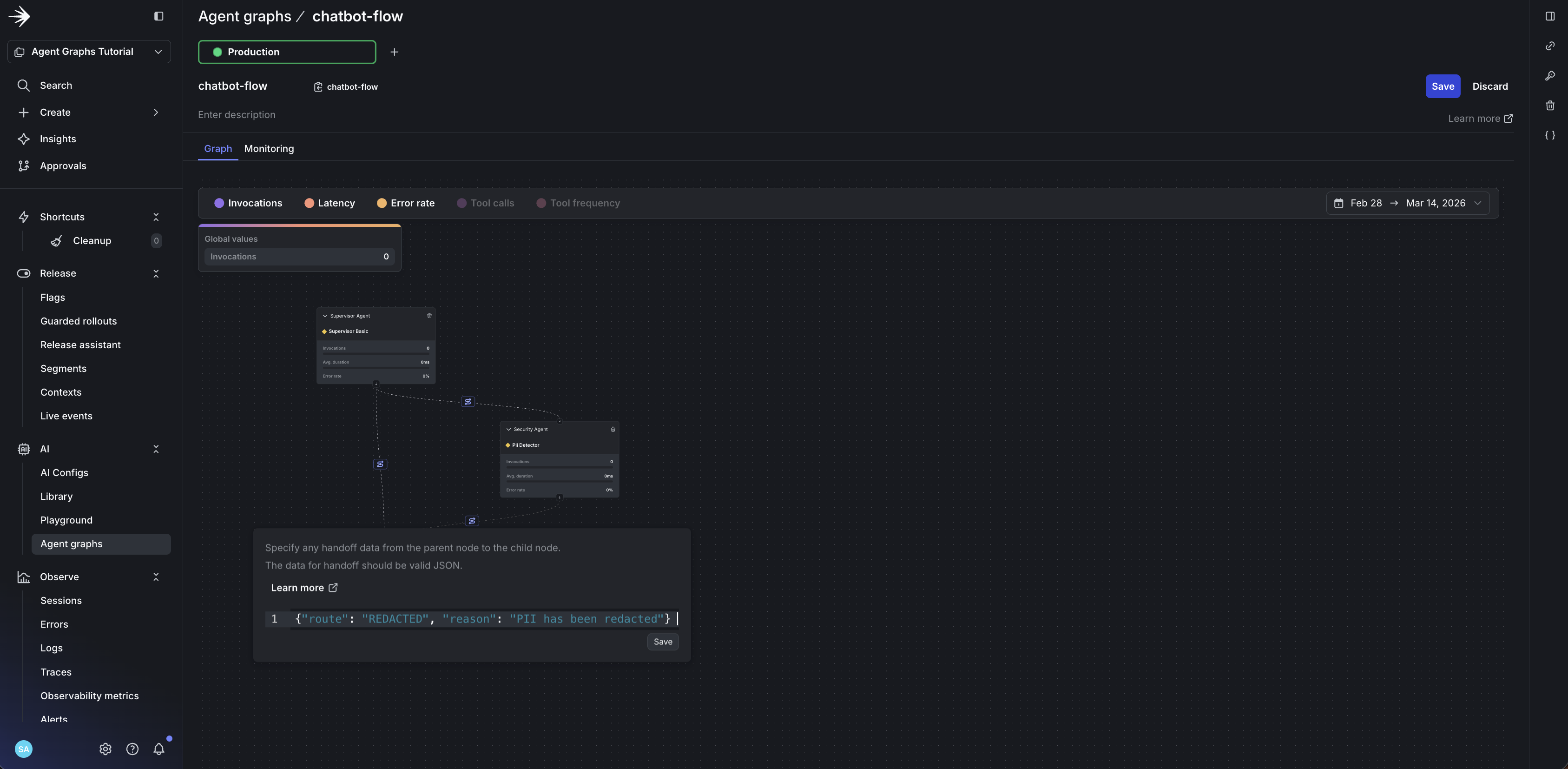
LaunchDarkly doesn’t execute your graph. It provides:
- Topology: Which nodes exist and how they connect
- Handoff metadata: Whatever JSON you put on edges
- Per-node AI Config: Model, instructions, tools for each agent
- Decides which edges to follow based on agent decisions
- Interprets handoff data however you want (the schema is yours)
- Executes the actual agents
Step 3: Add the SDK to Your Project
Install the LaunchDarkly AI SDK:Step 4: Integrate with Your Framework
This section walks through the integration code, starting with the building block (what runs at each node), then showing how nodes are orchestrated.The Generic Agent Pattern
The key to dynamic execution iscreate_generic_agent. Every node uses the same implementation—no agent registry, no hardcoded agent types:
The generic agent pattern means:
- No agent registry: Every node uses the same
create_generic_agentfunction - Config-driven behavior: Model, instructions, and tools all come from LaunchDarkly
- Dynamic routing: Valid routes are injected from graph edges, not hardcoded
- Minimal code changes: Add a new agent in LaunchDarkly, create its AI Config, add it to your graph, and it works—provided your runtime supports the node’s tools and output contract
The Agent
Service Class TheAgentService class is the entry point for processing messages through your Agent Graph:
Executing the Graph
The_execute_graph method fetches the graph from LaunchDarkly and uses traverse() with skip logic for conditional routing:
Skip Logic for Conditional Routing
Theexecute_node callback implements skip logic—the core pattern that enables conditional routing:
The
_routed_to set tracks which nodes should execute:-
Start: Add root node to
_routed_to -
traverse() visits each node: If node is in
_routed_to, execute it; otherwise skip -
After execution: Add the next node (based on routing decision) to
_routed_to
Routing Between Nodes
The_select_next_node method determines which node to route to based on the agent’s routing decision:
Step 5: Run It
With theAgentService wired up (as shown in Step 4), you can now process messages through your Agent Graph. The service handles:
- Building the LaunchDarkly context for targeting
- Fetching the graph and executing nodes via
traverse() - Tracking metrics for monitoring
- Returning the final response
Step 6: Monitor Agent Performance
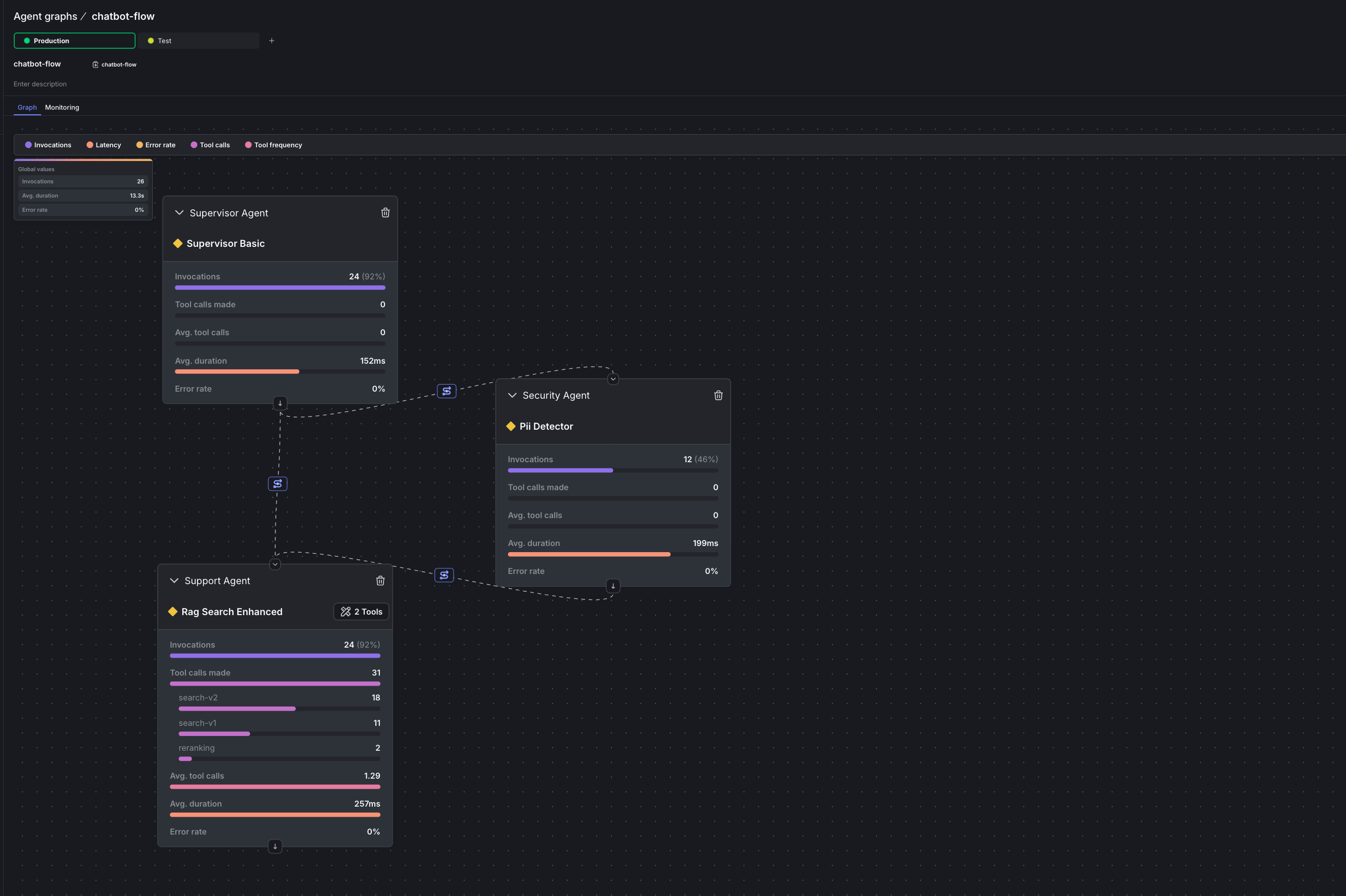
This is the key differentiator: monitoring happens on the graph itself, not in a separate dashboard. You see metrics overlaid on the same visual topology you built, so bottlenecks are immediately obvious. The sample repo includes full instrumentation: calls totracker.track_success(), tracker.track_error(), and tracker.track_tool_call() in the agent execution path. After running some traffic, open your Agent Graph to see the results.
Navigate to AI > Agent graphs > chatbot-flow. You’ll see a metrics bar at the top of the graph view where you can toggle different metrics on and off.
Metrics on the graph
Here’s what makes this different from traditional APM: the metrics appear directly on your workflow visualization. No mental mapping between a dashboard and your code. No correlating trace IDs. The slow node lights up on the graph. Turn on Latency to see duration data overlaid directly on your graph:- Total duration: The combined time for the entire graph invocation
- Per-node duration: How long each individual agent takes
Monitoring page
Click Monitoring to see all metrics over time. This view shows:- Latency trends: Duration per node over hours, days, or weeks
- Invocation patterns: Traffic flow through your graph
- Tool call breakdown: Which specific tools are being called and how often
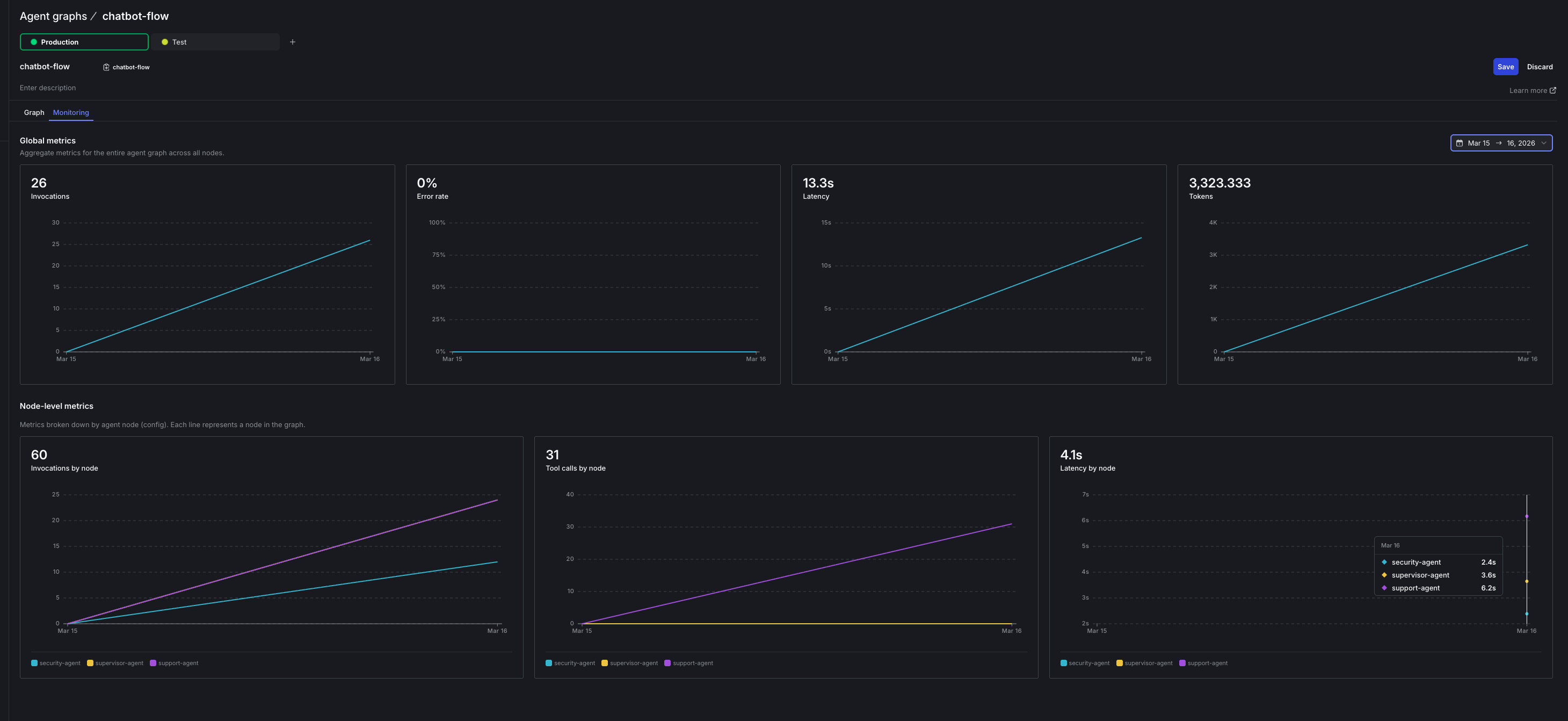
To see which specific tools are called, you need to track them in your code using the tracker. The SDK sends this data to LaunchDarkly, which displays it in the monitoring view.
Generate traffic to see metrics
Run the traffic generator from the sample repo to send queries through your graph:Detecting a slow agent
With traffic flowing, suppose the security-agent starts averaging 5 seconds per call. With latency metrics enabled on the graph, you see it immediately: the security-agent node shows a high duration value while other nodes stay fast. The invocation numbers also tell a story. If security-agent shows 50 invocations and support-agent shows 80, you know ~30 queries are bypassing security (the clean path). This helps you understand whether the slow agent is affecting most users or just a subset. Without Agent Graphs, you’d need custom logging, Datadog queries, and manual correlation. With Agent Graphs, you see the problem in 30 seconds.Step 7: Fix Without Deploying
The security-agent is slow because it’s usingclaude-sonnet-4 for PII detection. A smaller, faster model may be sufficient for this task.
In the LaunchDarkly dashboard, update the pii-detector variation:
- Change model from
Anthropic.claude-sonnet-4-20250514toAnthropic.claude-3-haiku-20240307
What just happened
- Traffic generator sent queries through the graph
- Monitoring showed the slow agent on the graph
- Model swap happened in the UI (or via Agent Skills)
- Your code automatically used the new configuration
Open
AI Agents SDK Integration (Conceptual) Agent Graphs work with multiple frameworks. This conceptual example shows how the pattern translates to OpenAI Agents SDK:Best Practices
Start simple: Begin with a linear graph (A → B → C) before adding conditional routing. Use handoff data for context passing: Include metadata like action type, reason, or state that the next agent needs to continue the workflow. Track everything: Calltracker.track_success() and tracker.track_error() in every node for complete visibility. Use graph_tracker.track_tool_call(tool_name) to track which tools agents invoke.
Test with targeting: Use LaunchDarkly targeting to route test users to experimental graph configurations.
Handle missing edges: Decide what happens when no edge matches a routing decision or when a target node is disabled. Recommend: fail closed, log diagnostics, and track routing failures.
Keep execution state request-scoped: Store execution state inside the context object (ctx) passed through traversal, not in instance-level variables. Treat graph traversal as request-scoped to avoid concurrency issues.
What You’ve Built
You now have a multi-agent system where:- Graph topology is externalized and self-documenting
- Routing logic is visible on edges, not buried in code
- Monitoring appears on the graph itself, not a separate dashboard
- Node-level control lets you disable a single agent without touching others, provided your executor checks node availability
- Multiple frameworks can consume the same graph metadata
Next Steps
- Agent Graphs Reference: SDK methods for
traverse,reverse_traverse,get_edges(), and handoff data - AI Configs Documentation: Learn more about variations, targeting, and experiments
- Agent Skills Tutorial: Manage AI Configs from your coding assistant
- Monitor AI Configs: Deep dive into metrics and dashboards
- Sample Repository: Complete code from this tutorial