Documentation Index
Fetch the complete documentation index at: https://launchdarkly-preview.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.

The Incident
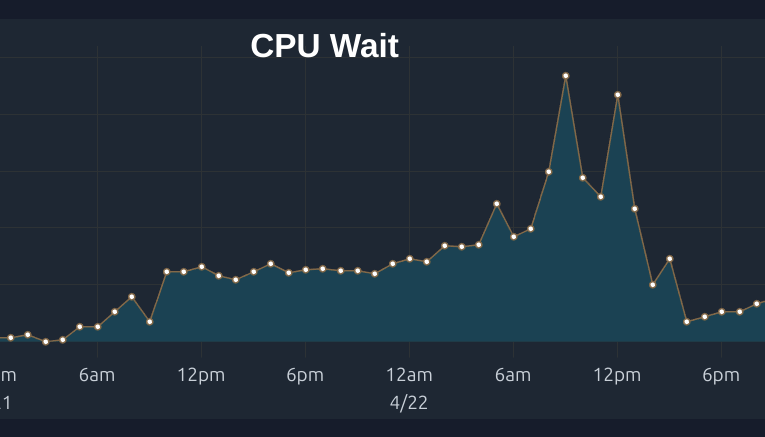
Sometime last year, we onboarded a large customer that sent close to 1 billion spans a day, adding another terabyte to our data ingestion. Beyond the total volume, the real problem with this was in the number of small batches of rows inserted into ClickHouse. Our Kafka queue responsible for buffering data started accruing a backlog, and we quickly noticed that the rate of trace insertion into ClickHouse was significantly lower than the number of new records added to Kafka.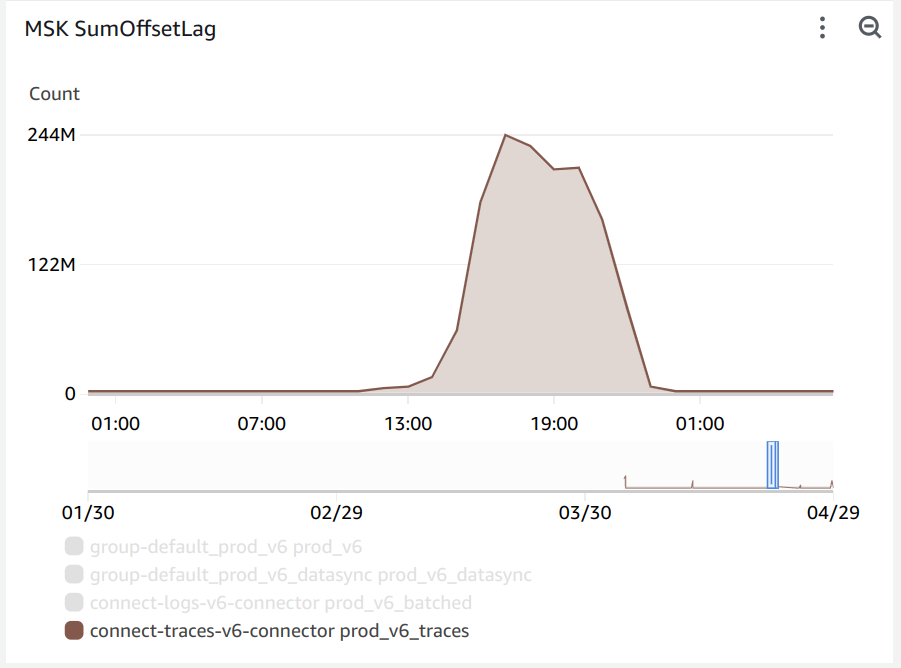
Reducing Merges - Batch Inserts
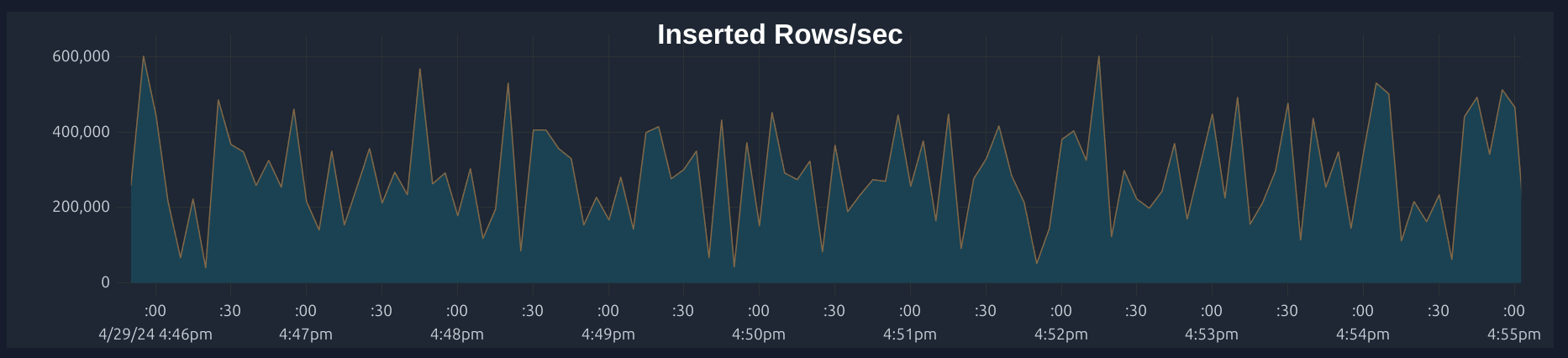
The first step to reducing CPU load on ClickHouse is using larger insert batches. While ClickHouse Cloud offers async inserts to perform individual inserts with the cloud cluster handling batching, we chose to use batchINSERT commands
as
a way to customize the size of batches on our end. A large batch size was particularly important to our workload as the
individual rows were on the order of 100KiB each.
Our first approach used a custom Golang worker that would read messages from Kafka, batch them per our settings, and
issue a single INSERT command with many values. Though this worked to ensure inserts were large, inserts were not
atomic
resulting in duplicate data being inserted during worker reboots.
We opted to use the ClickHouse Kafka Connect Sink that implements batched writes and exactly-once semantics achieved through ClickHouse Keeper.
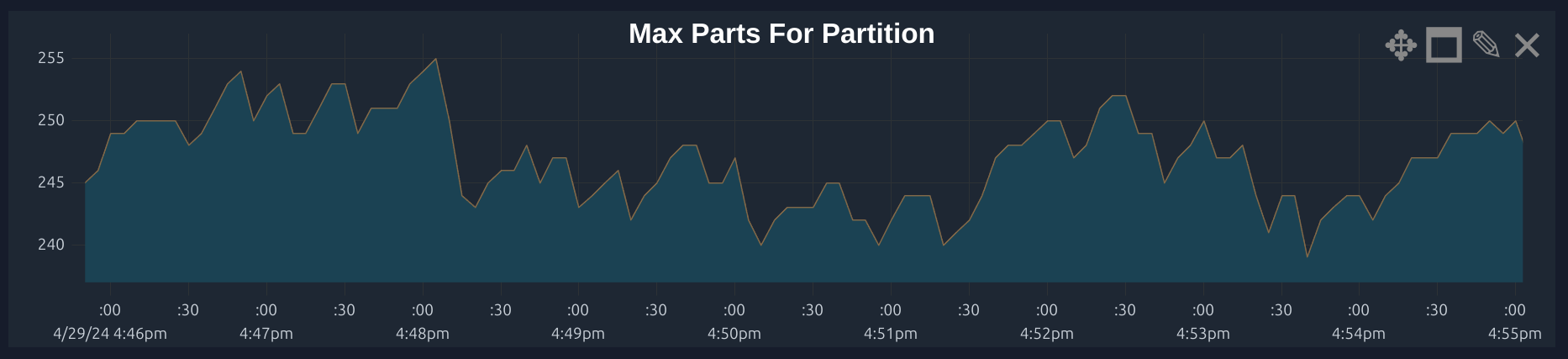
To ensure our changes had the right effect, we monitored the Max Parts graph in ClickHouse for the number of parts waiting to be merged. Read more on how this works from ClickHouse here.
Keeping Data in Wide Parts
CPU Usage during merges can also be incurred by the conversion of parts from compact to wide. When data is inserted compressed, it must be decompressed into the wide format for it to be merged. If inserting large batch sizes (100k+ rows at 10MB+ data), a table level setting that helps is usingmin_rows_for_wide_part=0, min_bytes_for_wide_part=0 to
make
sure that ClickHouse will keep inserted data as WIDE to avoid having to convert back and forth between the compact and
narrow format, since each conversion incurs a CPU cost.
Optimizing Order By Granularity
If a table is ordered by columns with high granularity, this will result in increased sorting of data when ClickHouse is merging parts. For instance, we found that switching ourORDER BY Timestamp to an ORDER BY toStartOfSecond(Timestamp) reduced the CPU load of merging since everything within the same minute would be grouped into the same part
without having to be sorted. The tradeoff occurs with query performance – a granular ORDER BY means that a SELECT
will load more parts that must be filtered and sorted, but this is well worth the reduced merging that must happen.
Another common use case for ordering is using a ID. However, adding the ID to the ORDER BY will require all rows to be
sorted by a value where each row’s value is unique. A better approach could be to use a truncated version of the ID
which would use the first N digits of the value to select a smaller range of rows to sort.
Checking Merge Levels
The performance of merges depends on a number of factors around the type of data and the way that it is inserted. Batch insertion often means that bulk merges may be more efficient. Observing the mergelevel helps understand
how many times data is re-merged within a part. If insertions are large, full part storage is more efficient since
the data is already in the right format.
You can also observe all current merges to understand what tables / partitions are causing the most.
min_bytes_for_full_part_storage setting. For instance,setting
min_bytes_for_full_part_storage=0 will ensure most parts use Full storage which may
be more efficient for future large merges as the part_storage_type data format will not have to be converted from Packed to Full.
Avoiding Use of Projections
Projections may be useful to automate switching between multiple views for querying data depending on the primary filter arguments. For example, a table may have a primary key ofORDER BY Timestamp allowing for efficient queries within a
time range. At the same time, you may be interested in querying that table by ID. The typical way to do that would be to
create a materialized view from the table with a different ORDER BY, and switching the query to select from the
materialized view when filtering by ID.
Projections offer an automated approach to choosing the source for the select, creating a materialized view for the data
but selecting the source automatically. However, with certain queries, the ClickHouse query plan may not select the
optimal source view for the data, and it limits your ability to further customize the materialized view. We found using
a materialized view and selecting manually as part of our application logic depending on the query pattern to be more
reliable.
TTL Optimization / Clearing Old Parts
It’s important to ensure most writes are coming to a few partitions to limit the number of parts that are being merged. Otherwise, ClickHouse will have to merge all parts to keep the data up to date. A table’sPARTITION BY clause will dictate how data is partitioned. For example, if a table is partitioned
by Timestamp,
data will be written to different parts based on the timestamp. If you have many concurrent writes with vastly different
timestamps, ClickHouse will have to merge many parts as the different writes will land in different active parts. This,
in turn, will increase background CPU activity.
In our application (this will depend on your use case), we ensure that most writes are coming to
a few partitions, limiting the number of parts that are being merged. We also set a TTL on our tables to clear out old
data, which helps with parts remaining active. You can always check how many parts are active by running the following
SQL query: